Power amplifiers are essential components in the overall performance and throughput of communication systems, but they are inherently nonlinear. The nonlinearity generates spectral re-growth, which leads to adjacent channel interference and violations of the out-of-band emissions standards mandated by regulatory bodies. It also causes in-band distortion, which degrades the bit-error rate (BER) and data throughput of the communication system.
To reduce the nonlinearity, the power amplifier can be operated at a lower power (that is, “backed off”) so that it operates within the linear portion of its operating curve. However, newer transmission formats, such as wideband code division multiple access (WCDMA) and orthogonal frequency division multiplexing (OFDM, WLAN/3GPP LTE), have high peak-to-average power ratios (PAPR); that is, large fluctuations in their signal envelopes. This means that the power amplifier needs to be backed off well below its maximum saturated output power in order to handle infrequent peaks, which result in very low efficiencies (typically less than 10%). With greater than 90% of the DC power being lost and turning into heat, the amplifier performance, reliability and ongoing operating expenses (OPEX) are all degraded.
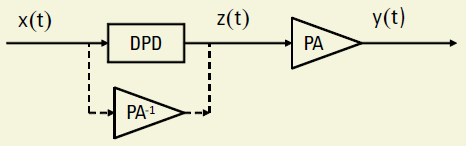
Figure 1. DPD-PA Cascade
DPD is one of the most cost-effective linearization techniques. It features an excellent linearization capability, the ability to preserve overall efficiency, and it takes full advantage of advances in digital signal processors and A/D converters. The technique adds an expanding nonlinearity in the baseband that complements the compressing characteristic of the RF power amplifier (Figure 1). Ideally, the cascade of the pre-distorter and the power amplifier becomes linear and the original input is amplified by a constant gain. With the pre-distorter, the power amplifier can be utilized up to its saturation point while still maintaining good linearity, thereby significantly increasing its efficiency. From Figure 1, the DPD can be seen as an “inverse” of the PA. The DPD algorithm needs to model the PA behavior accurately and efficiently for successful DPD deployment.
DPD implementations can be classified into memoryless models and models with memory.
Memoryless models focus on the power amplifier that has a memoryless nonlinearity, that is, the current output depends only on the current input through a nonlinear mechanism. This instantaneous non-linearity is usually characterized by the AM/AM and AM/PM responses of the power amplifier, where the output signal amplitude and phase deviation of the power amplifier output are given as functions of the amplitude of its current input. Both memoryless polynomial algorithm and Look-Up Table (LUT) based algorithm are two key algorithms for memoryless models.
Figure 2 shows the structure of applying the Look-up Table. There are two configurations according to the order of AM/AM and AM/PM. For the first configuration (AM/PM then AM/AM), the input amplitude values for AM/PM LUT and AM/AM LUT are the same. For the second configuration (AM/AM then AM/PM), the input amplitude values for AM/AM LUT and AM/PM LUT are different.
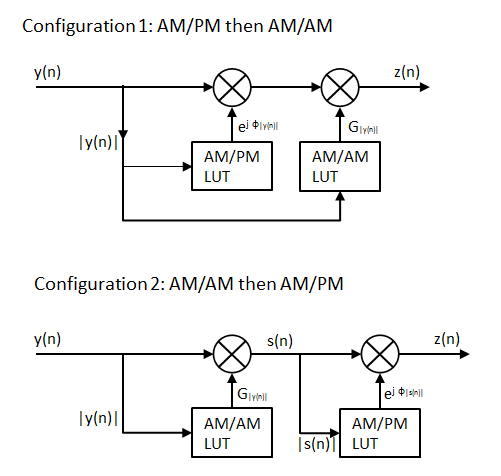
Figure 2. Look-up Table Structure
Memory model is commonly used as the signal bandwidth gets wider, such as in WCDMA, mobile WiMAX and 3GPP LTE and LTE-Advanced (up to 100 MHz bandwidth, 5 component carriers of carrier aggregation ). For wider bandwidth, power amplifiers begin to exhibit memory effects. This is especially true for those high power amplifiers used in wireless base stations. The causes of the memory effects can be attributed to thermal constants of the active devices or components in the biasing network that have frequency dependent behaviors. As a result, the current output of the power amplifier depends not only on the current input, but also on the past input values. In other words, the power amplifier becomes a nonlinear system with memory. For such a power amplifier, memoryless pre-distortion can achieve only very limited linearization performance. Therefore, digital pre-distorters must have memory structures.
The most important algorithm for models with memory for Digital pre-distortion implementation is Volterra series and its derivatives. The most general way to introduce memory is to use the Volterra series. However, the large number of coefficients of the Volterra series makes it unattractive for practical applications. Therefore, there are several Volterra’s derivatives including Wiener, Hammerstein, Wiener–Hammerstein, parallel Wiener structures, and memory polynomial model are popular in digital pre-distorters. The so-called “memory polynomial” is interpreted as a special case of a generalized Hammerstein model and is further elaborated by combining with the Wiener model.
To construct digital pre-distorters with memory structures, there are two types of approaches. One type of approach is to first identify the power amplifier and then find the inverse of the power amplifier directly. This approach is named as direct learning architecture (DLA). However, obtaining the inverse of a nonlinear system with memory is generally a difficult task. Another type of approach is to use the indirect learning architecture (IDLA) to design the pre-distorter directly. The advantage of this type of approach is that it eliminates the need for model assumption and parameter estimation of the power amplifier.
The indirect learning architecture for the digital pre-distorter is shown as following. N7614C Signal Studio for Power Amplifier Test 2022 adopts this structure.
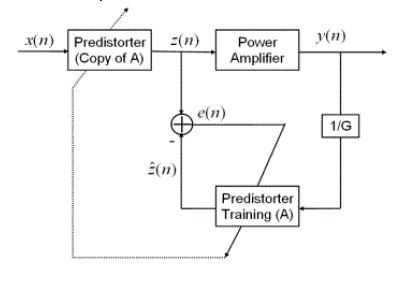
Figure 3. Indirect Learning Architecture
In Keysight N7614C Signal Studio for Power Amplifier Test 2022, both memory polynomial and Volterra series algorithm are implemented.
The following figure shows the memory polynomial structure. If Q=0, the structure in the following figure becomes memoryless polynomial.
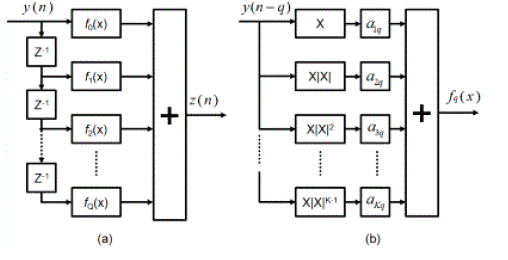
Figure 4. Memory Polynomial Structure
The structure of Volterra series is shown below.
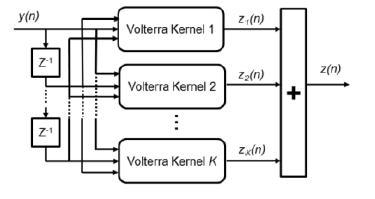
Figure 5. Volterra Series Structure